Namespaces¶
The most important concept to understand when working with complex XML documents is the namespace. A namespace is nothing more than a map from names to objects, partitioned into groups within which the names must uniquely identify an object.
A namespace is identified by its name, which is a URI. Although it is common to use
URIs like http://www.w3.org/2001/XMLSchema as namespace names, the name
is simply an opaque identifier: it does not have to resolve to a Web site or
anything helpful. dinner:ParsnipsOnTuesday is a perfectly valid
namespace name.
Equally, namespaces and XML schemas are not the same thing. A schema is
simply a mechanism for specifying the contents of a namespace. It is common
to use the include directive in XMLSchema to combine multiple schema
into a single namespace. It is less common, though equally valid, to use
xmlns or xs:schemaLocation to select alternative schemas to use for
the same namespace in different instance documents, as in the dangling type pattern.
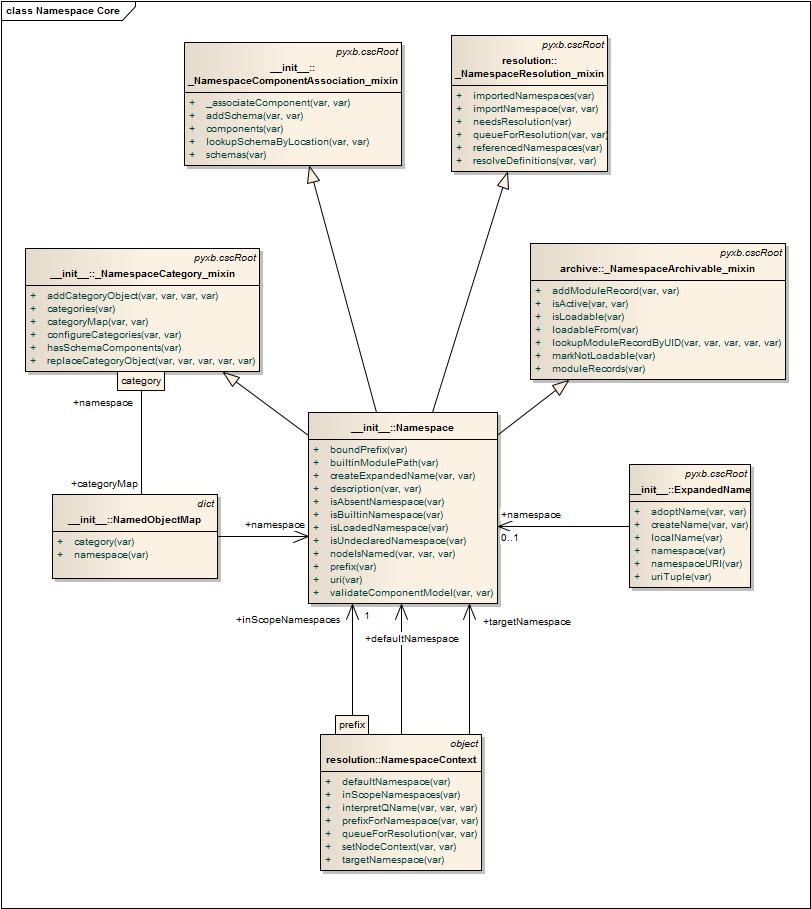
This diagram shows the class structure of the PyXB namespace infrastructure.
The central object is the pyxb.namespace.Namespace. Four mix-in
classes provide implementations of separate namespace functions.
pyxb.namespace.ExpandedName is used ubiquitously to pair local names
with their namespaces. pyxb.namespace.NamedObjectMap maps names to the objects
(generally, schema components) for a particular category of object. The
pyxb.namespace.NamespaceContext class provides information related to
the use of namespaces in XML documents, including mappings from prefixes to
namespaces.
Namespace Category Maps¶
The pyxb.namespace._NamespaceCategory_mixin provides support for
discrete categories of named objects. It allows arbitrary,
runtime-identified, groups of objects to be registered in individual
dictionaries within the namespace. For example, XML Schema require that type
definitions, element declarations, and attribute declarations be distinct
categories of named objects in a namespace. PyXB also maintains separate
categories for attribute groups, model groups, identity constraint
definitions, and notation declarations, which also must be unique within their
category.
Other groups of objects can be stored in a namespace. For example, the WSDL definition of a service may choose to use the same namespace name for its types as for its definitions, adding services, ports, messages, bindings, and portTypes as named objects that can be identified.
Namespace Component Associations¶
The pyxb.namespace._NamespaceComponentAssociation_mixin provides
support for associating schema components with a namespace. Of particular
interest is that a namespace can be comprised of components defined from
multiple sources (generally, distinct schema documents). In addition, there
are anonymous components (e.g., complex types defined within element members
of complex types) which are implicitly associated with the namespace although
they cannot be named within it. These must all be stored within the namespace
so that a complete set of bindings can be generated in a single Python module.
Namespace Resolution¶
Named objects are often associated with namespaces through XML elements in a document. For example:
<xs:attribute xmlns:xs="http://www.w3.org/2001/XMLSchema"
name="vegetable" type="xs:string" default="parsnip"/>
specifies an attribute declaration. In turn, references to names appear
within XML elements, usually as values of specific attributes. The type
portion of the attribute declaration above also identifies an object by name,
and it must be possible to resolve the named object. The work involved in
associating names with schema components is encapsulated in the
pyxb.namespace.resolution._NamespaceResolution_mixin class.
The following concepts are important to understand:
- An NCName (“no-colon name”) is an identifier, specifically one without any colon (”:”) characters, serving as a local name.
- A QName (“qualified name”) is an local name with an optional prefix, separated from it by a colon, which identifies a context for the local name.
- The prefix is mapped using xmlns attributes to a namespace name, which is a URI.
- The combination of a namespace URI and the local name comprise an expanded
namespace name, which is
represented by
pyxb.namespace.ExpandedName. - The category within which the local name must be resolved in the namespace
is determined through external information, in the above case the fact of
the QName’s appearance in a
typeattribute in anattributedeclaration of an XML schema.
pyxb.namespace._NamespaceCategory_mixin is used to define the set of
categories supported by a namespace and to add named objects to those
categories. A name is resolved when the object with which it is
associated has been identified. Objects are resolved when any names on
which they depend have been resolved.
pyxb.namespace.resolution._NamespaceResolution_mixin provides a mechanism to
hold on to names that have been encountered but whose associated objects
have not yet been resolved (perhaps because the named object on which they
depend has not been defined).
Because one named object (e.g., a model group definition) might require
resolution of another (e.g., an element reference), resolution is an iterative
process, implemented by
pyxb.namespace.resolution._NamespaceResolution_mixin.resolveDefinitions,
and executed when all named objects have been added to the namespace. It
depends on pyxb.namespace.resolution.NamespaceContext to identify named
objects using the
pyxb.namespace.resolution.NamespaceContext.interpretQName method.
Expanded Names¶
An pyxb.namespace.ExpandedName instance couples a local name with
(optionally) a namespace, resulting in a QName. This class also integrates
with namespace categories, permitting lookup of the object with its name in a
specific category by using the category name as a method. For example, the
following two expressions are equivalent:
# Short-hand method
en.typeDefinition()
# Detailed equivalent
en.namespace().categoryMap('typeDefinition').get(en.localName())
Both produce the type definition with the given name, or None if there is
no such definition. The short-hand method interface works for any category
defined within the expanded name’s namespace; it is not limited to the
standard set of component categories.
Methods are also present to test whether the name matches a DOM node, and to retrieve the named attribute (if present) from a DOM node.
In this version of PyXB, the hash codes and comparison methods for
ExpandedName have been overridden so that
an expanded name with no namespace is treated equivalently to the string value
of the local name. This simplified management of default namespace lookups in
earlier versions of PyXB, but may no longer be necessary; reliance on this
feature is discouraged.
Namespace Context¶
Namespaces in XML specifies how the
xmlns attributes are used to associate prefix strings with namespaces.
The pyxb.namespace.NamespaceContext class supports this by associating
with each node in a DOM document the contextual information extracted from
xmlns and other namespace-relevant attributes.
The namespace context consists of three main parts:
- The default namespace specifies the namespace in which unqualified names are resolved.
- The target namespace is the namespace into which new name-to-component associations will be recorded.
- The in-scope namespaces of a DOM node are those which can be identified by a prefix applied to names that appear in the node.
Methods are provided to define context on a per-node basis within a DOM structure, or to dynamically generate contexts based on parent contexts and local namespace declarations as needed when using the SAX parser.
Other Concepts¶
Absent Namespaces¶
Some schemas fail to specify a default namespace, a target namespace, or both. These cases are described by the term “absent namespace”; sometimes it is said that an object for which the target namespace is absent is in “no namespace”.
If the target namespace for a schema is absent, we still need to be able to
store things somewhere, so we represent the target namespace as a normal
pyxb.namespace.Namespace instance, except that the associated URI is
None. If in the same schema there is no default namespace, the default
namespace is assigned to be this absent (but valid) target namespace, so that
QName resolution works. Absence of a target namespace is the only situation
in which resolution can succeed without some sort of namespace declaration.
The main effect of this is that some external handle on the Namespace instance
must be retained, because the namespace cannot be identified in other
contexts. PyXB supports this by defining a Namespace variable within each
binding module, thus allowing access to the namespace instance via syntax like
pyxb.bundles.wssplat.wsdl11.Namespace.
Storage of Namespaces¶
In PyXB, when the Component Model is used to define various elements,
attributes, and types by representing them in Python instances, those instance
objects are stored in a pyxb.namespace.Namespace instance. In addition
to generating code corresponding to those objects, it is possible to save the
pre-computed objects into a file so that they can be referenced in other
namespaces.
PyXB uses the Python pickling infrastructure to store the namespace component
model into a file in the same directory as the generated binding, but with a
suffix .wxs. When a schema is processed that refers to a namespace, the
serialized component model for the namespace is read in so that the referring
namespace can resolve types in it.
The Namespace Archive Model¶
Recall that the contents of a namespace can be defined from multiple sources. While in the simplest cases the namespace is defined by combining components from one or more schemas, the set of schemas that define a namespace may be different for different documents. One way this is used is the dangling types<http://www.xfront.com/VariableContentContainers.html#method4> pattern.
Another not uncommon situation is to use a namespace profile, which is a subset of the full namespace intended for use in a particular application. For example, the Geography Markup Language defines three profiles denoted “GML-SF” for “simple features”; these profiles do not include the more complex structures that are needed for unusual situations.
Finally, some use cases require that a namespace be extended with application-specific information provided in a schema that adds to rather than replaces the base namespace definition. As with profiles these extensions should be provided in separate Python modules, but unlike profiles the original binding must be imported separately to provide the application’s perspective of the full namespace content.
To support these cases, PyXB must:
- Support distinct Python binding modules for one namespace (e.g., dangling type implementations and profiles)
- Support shared Python binding modules for one namespace (e.g., a base namespace with application-specific extensions)
- Ensure the component model for each binding module is retained within a single archive regardless of whether that component model is complete for the module’s namespace
Naive management of these multiple information sources will cause havoc, since namespaces do not allow multiple objects to share the same name.
The relations of the various classes involved in storing namespace data are depicted in the following diagram:

The namespace archive facility must support the following situations:
- The archive stores the complete set of components for a single namespace (most common)
- The archive stores components from multiple namespaces which are interdependent, but together completely define the expected contents of the namespaces
- The archive stores a complete subset of the standard components of a namespace (the profile situation)
- The archive extends a namespace with additional components, often required for a particular application. It is usually necessary to read another archive to determine the full namespace content.
Because of interdependencies between namespaces stored in a single archive, archives are read as complete entities: i.e., from a single archive you cannot read the components corresponding to one namespace while ignoring those from another.
The component model for a namespace is read from a namespace archive only when
it is necessary to generate new bindings for a namespace that refers to it,
through import or namespace declarations. The component model is defined by
invoking the pyxb.namespace.Namespace.validateComponentModel method.
Within an archive, each namespace can be marked as private or public. When the component model for a namespace is validated, all archives in which that namespace is present and marked public are read and integrated into the available component models.
When an archive is read, namespaces in it that are marked private are also integrated into the component model. Prior to this integration, the namespace component model is validated, potentially requiring the load of other archives in which the namespace is marked public.
The contents of the namespace archive are:
- A set of
pyxb.namespace.archive._ModuleRecordinstances which identify namespaces and mark whether they are public or private in the archive. Each instance in turn contains (for namespaceA):- the set of
pyxb.namespace.archive._ObjectOrigininstances which identify the origins for components that are defined in the archive. In turn, each of these origins identifies by category and name the objects that were defined by this origin and consequently are stored in the containing archive. Due to use of the include directive, multiple origins may be associated with a single module record - the set of
pyxb.namespace.Namespaceinstances that were referenced byA. This includes namespaces that were imported into one of the origin objects, as well as those that were incorporated simply through reference to an object in a declared namespace
- the set of
- The objects within the namespace that were defined by the various origins
In addition to the raw component model, the namespace archive includes the names of the Python modules into which bindings for each namespace were generated.